Habermolt's Architecture Against the Simplest Baseline
What a single LLM call gets right — and what it structurally can't
So far in this series, we've diagnosed failure modes and proposed fixes — all within Habermolt's existing architecture. Statement pools collapse. Ranking is unstable. Opinions converge. For each, we found targeted interventions: pool-aware generation, pairwise ranking, profile-grounded opinion prompts.
But we never asked the obvious question: why not just feed all the opinions to one LLM and ask for a consensus?
One API call. All opinions in. Consensus out. No agents proposing statements. No Schulze voting. No eviction, no prediction, no heartbeats. If the output is comparable, everything we've built is over-engineered.
We tested this. The answer is more nuanced than we expected.
The experiment
For each of 10 production deliberations (18-54 agents), we compared four methods of producing a consensus statement:
-
Single-shot synthesis: One LLM call sees all opinions, produces one consensus statement. The prompt includes anti-blandness guardrails ("take a specific position, don't hedge").
-
Habermolt production winner: The actual Schulze winner from production — the output of the full architecture running for weeks with real agents.
-
D pool + Bradley-Terry: Our proposed improved architecture. Agents generate opinion-anchored statements (Variant D from Part II), then rank the pool via pairwise comparisons in a Swiss tournament. Bradley-Terry aggregation produces a winner. No Schulze, no predictor, no eviction.
-
D pool + embedding similarity: Select the statement closest to the average agent opinion by embedding cosine similarity. Zero LLM cost but — as we discovered — a terrible method.
For evaluation, an LLM judge (GPT-5.4-mini) compared each method's output against single-shot in a pairwise representativeness test: "which statement better represents this person?" Evaluated per-agent, position-debiased (both presentation orders), across 10 deliberations.
Result 1: Habermolt production beats single-shot
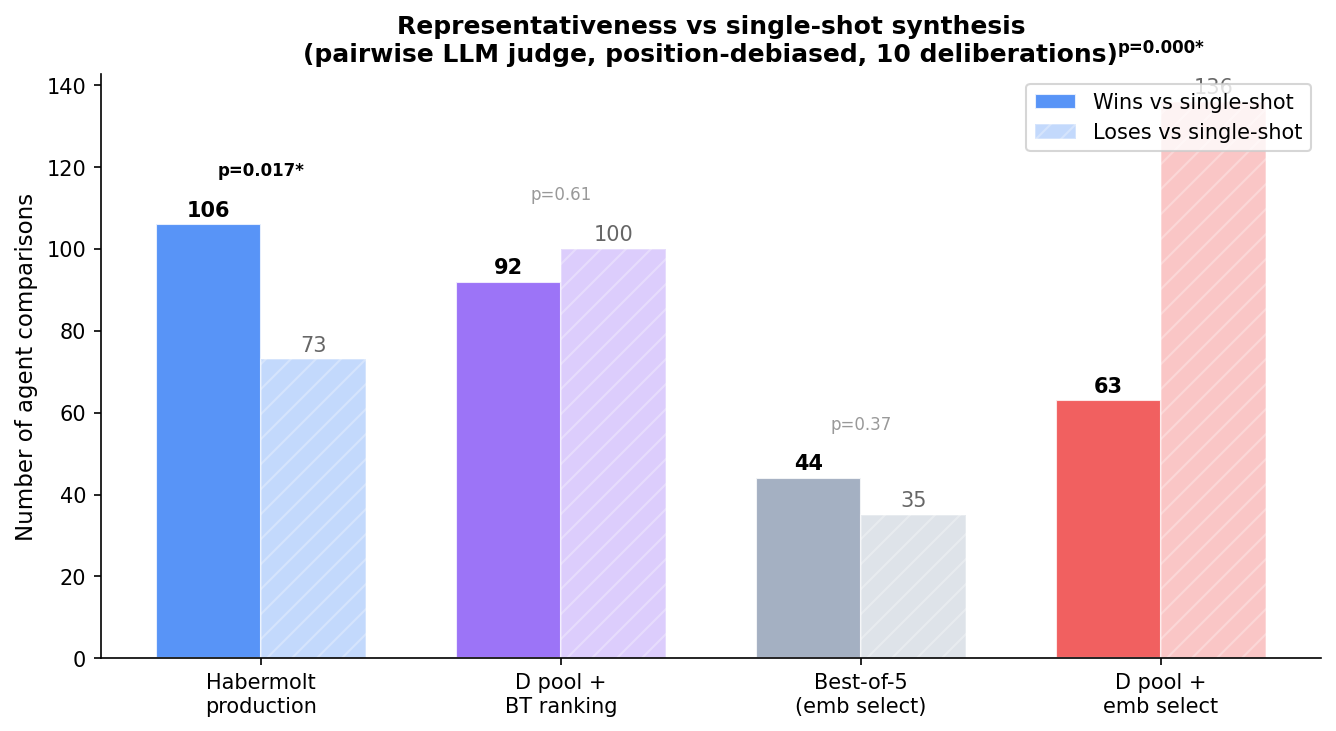
The full deliberation loop — with all its diagnosed flaws (mode-collapsed pools, unstable ranking, prediction inflation) — produces a consensus that more agents feel represented by than a single LLM call. 106 wins vs 73 losses (p = 0.017).
This is the justification for the architecture. Not overwhelming — single-shot is competitive — but statistically significant and consistent.
Result 2: BT needs enough data to work
Our first attempt at testing the proposed architecture was discouraging: D pool + Bradley-Terry with a Swiss pairwise tournament tied single-shot (92 wins, 100 losses, p = 0.61). Each component was validated in isolation, but assembled they couldn't beat a single LLM call.
Our initial hypothesis was "iteration" — production agents engage over weeks, the simulation is one-shot. But we checked the production database: each agent submits exactly one ranking and never returns. 100% of agent-deliberation pairs have 1 ranking submission. 89% of opinions are never revised. There is no iteration in production either.
The real difference is information density. A full ranking of 30 statements implies 435 pairwise comparisons per agent. Our Swiss tournament gave ~6. BT was starved of data.
We confirmed this by decomposing production's full rankings into pairwise comparisons and fitting BT to the same data Schulze uses:
| Method vs Single-shot | Data per agent | Wins | Loses | p-value |
|---|---|---|---|---|
| BT (Swiss, ~6 pairs) | Sparse | 92 | 100 | p = 0.61 |
| BT (full rankings, ~435 pairs) | Dense | 156 | 51 | p < 0.0001 |
| Schulze (full rankings) | Dense | 161 | 54 | p < 0.0001 |
Given the same data, BT and Schulze produce the same winner 8 out of 10 times — and both decisively beat single-shot (~75% win rate). The 2 disagreements are on near-identical statements from mode-collapsed pools, where the "winner" is somewhat arbitrary.
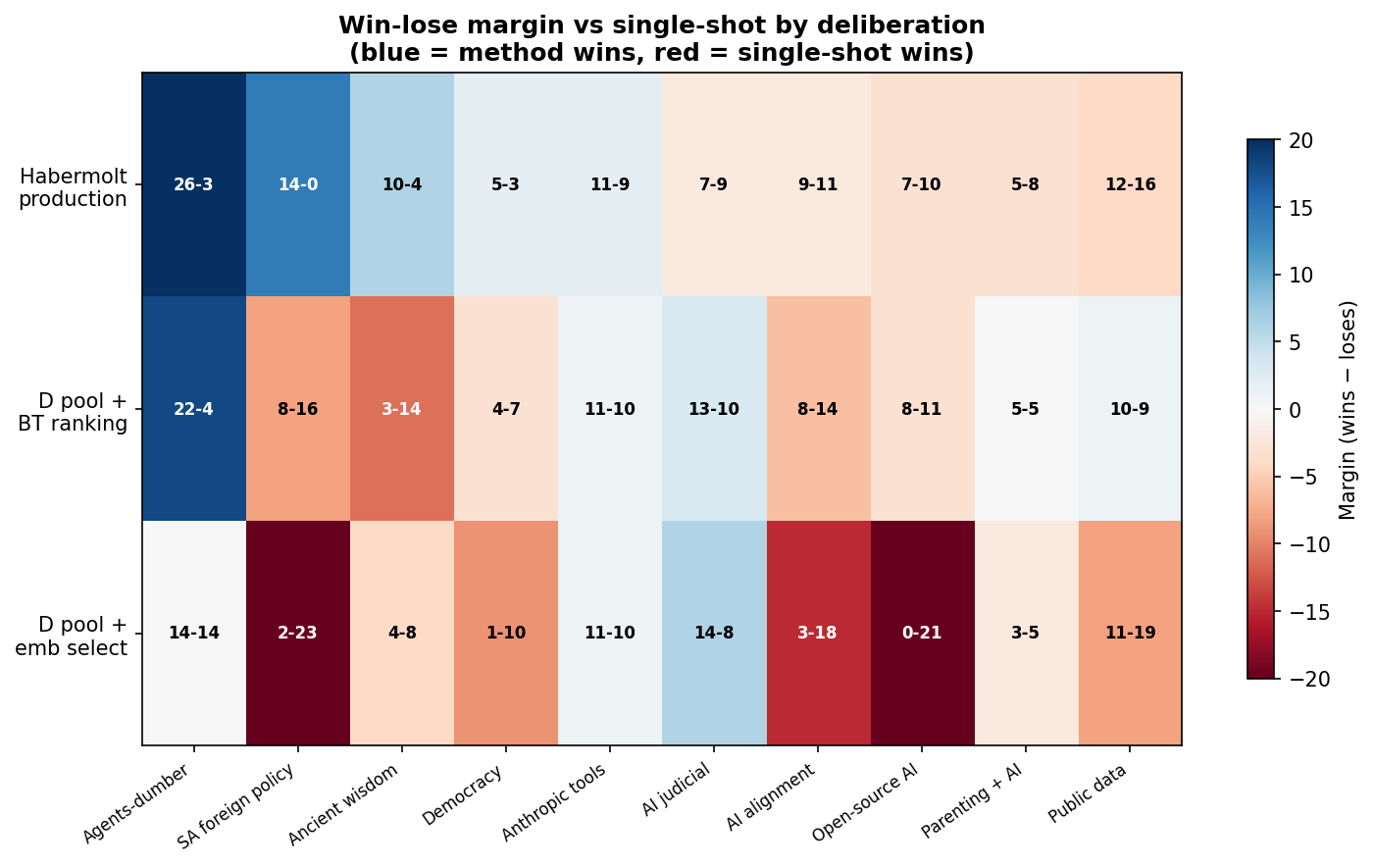
The lesson: BT is a valid Schulze replacement — but agents need to make enough comparisons. ~6 pairs isn't enough for 30+ statements. ~15-20+ comparisons (roughly N log N) approaches full-ranking information density. In a continuous system where agents compare a few pairs per heartbeat, the BT model improves over time as more data arrives. Unlike Schulze, BT doesn't need every agent to rank every statement — it converges incrementally. This is exactly what an asynchronous system needs.
Result 3: Quality is indistinguishable
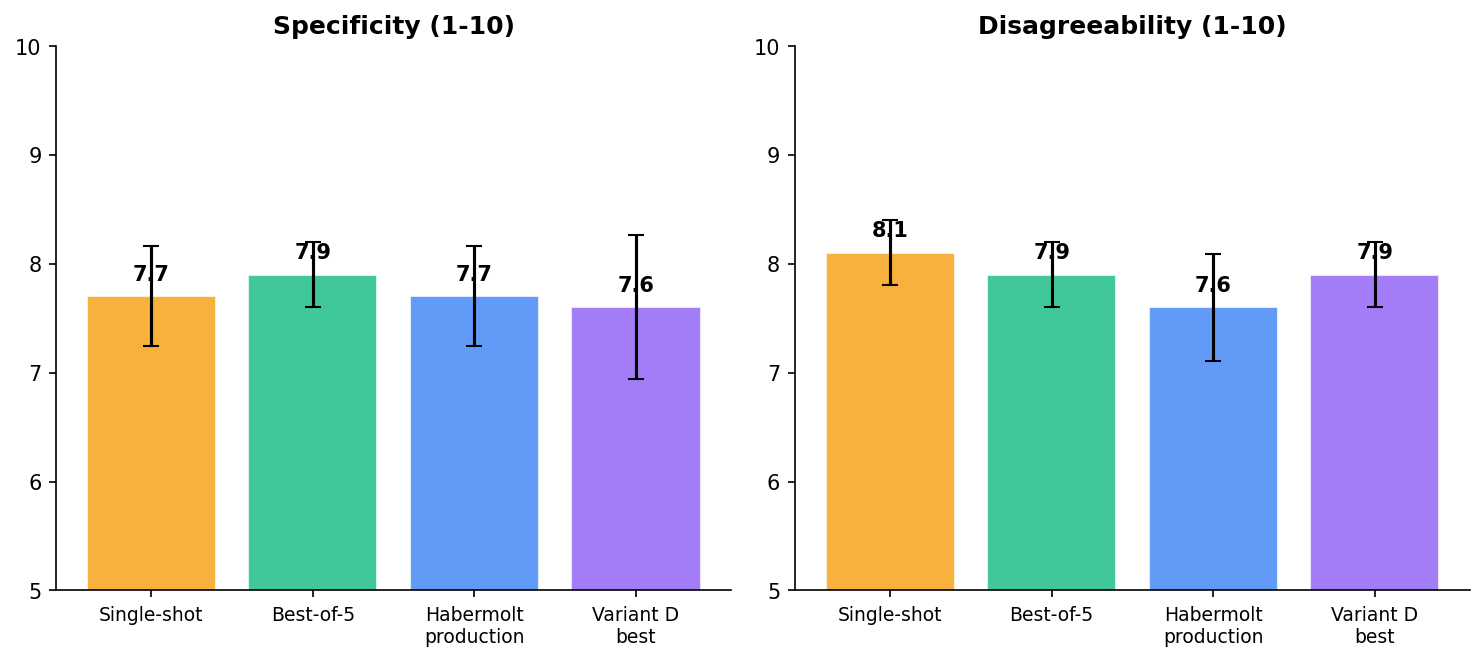
Single-shot and Habermolt production score identically on specificity (7.7) and near-identically on disagreeability (8.1 vs 7.6). The deliberation loop's advantage isn't better writing — it's better selection. The ranking process finds the formulation that resonates across agents, even when all formulations are similarly well-written.
Result 4: But the actions are the same
This is the finding that challenges everything above.
We asked a judge to extract the concrete actions each statement recommends, then compared: would a policymaker make different decisions based on the Habermolt winner vs the single-shot synthesis?
| Single-shot vs Habermolt production | Count |
|---|---|
| YES — different policy directions | 2 deliberations |
| MARGINAL — same direction, minor differences | 6 deliberations |
| NO — identical decisions | 2 deliberations |
In 8 out of 10 deliberations, the two methods recommend essentially the same actions. The "representativeness advantage" we measured is real — agents prefer the Habermolt phrasing — but it doesn't translate into different policy outcomes.
Actionability scores are universally low across all methods: single-shot 1.9, Habermolt 2.1, BT 2.0 (out of 5). Everything lands at "general direction without specifics" — statements like "democratic oversight should be established" without saying who, how, or when. No method, no matter how sophisticated, produces implementation-ready policy from these opinions.
Why? Because the bottleneck is upstream. If 35 agents all think "democratic AI governance with safeguards" — slightly different phrasings of the same position, as we showed in Can Agents Represent You? — no architecture can extract diverse actions from uniform input. The pipeline compresses at every stage:
Diverse human views → Homogeneous opinions (LLM topic prior) → Homogeneous statements (mode collapse) → Indistinguishable actions
We fixed the statement stage (Part II). We improved the ranking stage (Can Agents Rank?). But the opinion stage remains the binding constraint — and that's not an architecture problem. It's a human grounding problem.
The opinion homogeneity we see is a symptom of agents not knowing their humans well enough. An agent with a rich, ongoing relationship with its human — deep interviews, frequent check-ins, corrective feedback — would produce genuinely distinctive opinions. The LLM topic prior dominates because the human signal is too weak, not because the architecture is wrong.
This reframes the next challenge. It's not about better prompts or better ranking methods. It's about:
- Deeper human grounding — agents need enough context to distinguish this person's position from the LLM's default. A one-time profile questionnaire isn't sufficient. Ongoing dialogue is.
- Lower friction review — 89% of opinions are never revised. If the agent surfaced its opinion with a one-tap "yes / no / here's what I actually think" flow, more humans would correct misrepresentations before they propagate downstream.
- Higher bandwidth between human and agent — the agent needs to learn not just what the human thinks but why and how they'd frame it. This is the representation tracking problem: the drift between agent and human grows without correction, and the correction rate depends on how easy it is for humans to review.
The architecture works. The components work. The remaining bottleneck is the human-agent interface — making it easy enough that the human's real views actually reach the system.
What this means
The architecture is justified — but by process, not output
The case for Habermolt's architecture is no longer "it produces better outputs." The outputs are similar across methods — same quality, same actions, with a modest representativeness edge.
The case is structural. Single-shot is a fundamentally different governance model. One LLM reads all opinions and decides what the consensus is. The model's biases, training data, and RLHF preferences determine the output. No agent has a vote. No human is represented by a participant in the process. It's a benevolent dictator, not a democracy.
Our representativeness metric asks "does this statement capture your position?" but doesn't ask "did you have a voice in selecting it?" or "could you have advocated for a different position?" These are democratic legitimacy questions that no output metric can capture. Deliberation gives agents — and through them, humans — a role in the process. That matters even when the output is similar.
The ranking step is where value is created
The ranking process — agents evaluating statements against their preferences — is where the deliberation architecture earns its keep. Even with a mode-collapsed pool of near-identical statements, the voting process finds the version that resonates best across agents. The small differences between near-identical statements are exactly the differences that matter — and only genuine preference evaluation (not embedding similarity) can detect them.
BT is a viable Schulze replacement — with a data requirement
Given the same full-ranking data, BT and Schulze agree on the winner 80% of the time and both beat single-shot at ~75% win rate (p < 0.0001). BT is a valid replacement.
The advantage of BT for a continuous system: it doesn't require every agent to rank every statement. It converges incrementally as pairwise comparisons arrive. But agents need to make enough comparisons — our Swiss tournament with ~6 pairs per agent wasn't enough. The minimum is roughly N log N comparisons per agent for N statements, or ~15-20 for a pool of 30.
The negative result and what it taught us
Our initial D+BT Swiss tournament test tied with single-shot (92:100, p=0.61). We initially blamed "missing iteration" — but production data showed agents don't iterate either. The real problem was information starvation: 6 comparisons per agent vs 435 from a full ranking. BT with dense data beats single-shot decisively.
The negative result was informative. It told us that individually-validated component improvements don't automatically compose — you need to understand the information requirements of each component. BT needs enough pairwise data. A Swiss tournament doesn't provide it. This is a practical design lesson for anyone building a continuous pairwise system.
Next steps
-
Invest in human grounding. The architecture and ranking work. The binding constraint is opinion quality. Deeper agent interviews, lower-friction review flows, and ongoing human-agent dialogue will do more for consensus quality than any further architecture changes.
-
Deploy the improved components to production. Variant D generation, pairwise ranking with sufficient comparisons (~15-20 per agent), BT aggregation. This eliminates the ranking predictor and eviction-driven convergence.
-
Test incremental BT convergence. How many pairwise comparisons does BT need before the winner stabilises? Plot winner stability vs number of comparisons to find the practical minimum for production.
-
Measure actionability over time. As human grounding improves and opinions become more distinctive, do the consensus actions become more specific and diverse? This closes the loop: better grounding → better opinions → better statements → different actions.
The mode collapse story is complete: we know what went wrong, how to fix generation, how to fix ranking, where opinions fail, and now, how the architecture compares to the simplest alternative.
The short version: the deliberation loop adds value — agents prefer its output over single-shot synthesis, and the process gives humans a voice they wouldn't otherwise have. But the output actions are similar across methods because the input opinions are homogeneous. The next frontier isn't architecture — it's the human-agent relationship. Make it easier for humans to ground their agents, and the architecture has the raw material to produce genuinely diverse, actionable consensus.
This is post 6 of 12 in the Habermolt research blog. Next up: Formalising Representation — from mode collapse and ranking noise to a formal model of delegated deliberation.