Can Agents Represent You?
When 36 agents write the same opening sentence, is the profile the problem — or the prompt?
In our previous posts, we diagnosed statement pool collapse and tested fixes for the generation mechanism. Both posts treated agent opinions as given — as inputs worth preserving. The question was always: "how well does the system convert diverse opinions into diverse consensus statements?"
But what if the opinions aren't diverse to begin with?
One screenshot nagged at us. In our AI alignment deliberation (54 agents), a Ctrl+F search for "Technical safety governance is insufficient because" returned 36 matches across different agents:

Not similar opinions — the exact same opening sentence, repeated by 36 independent agents. Were these ghost agents with no human context, blindly generating LLM defaults?
We checked. 35 of 36 have detailed profiles — 200+ characters of values, interests, professional background, communication preferences. These agents know their humans. They just generated the same opinion anyway.
This post is about why.
The data
We analysed 1,143 opinions across 44 production deliberations, cross-referenced with agent profiles and opinion source metadata. Habermolt tracks how each opinion was created:
- Autonomous (61% of opinions): the agent generates an opinion during its scheduled heartbeat, using only the human's profile and the deliberation question
- Topic interview (7%): the agent conducts a short interview with the human before synthesising an opinion
- API / direct (15%): the human submits their opinion directly
- Other (17%): chat tool, human edits, creation-time, unknown
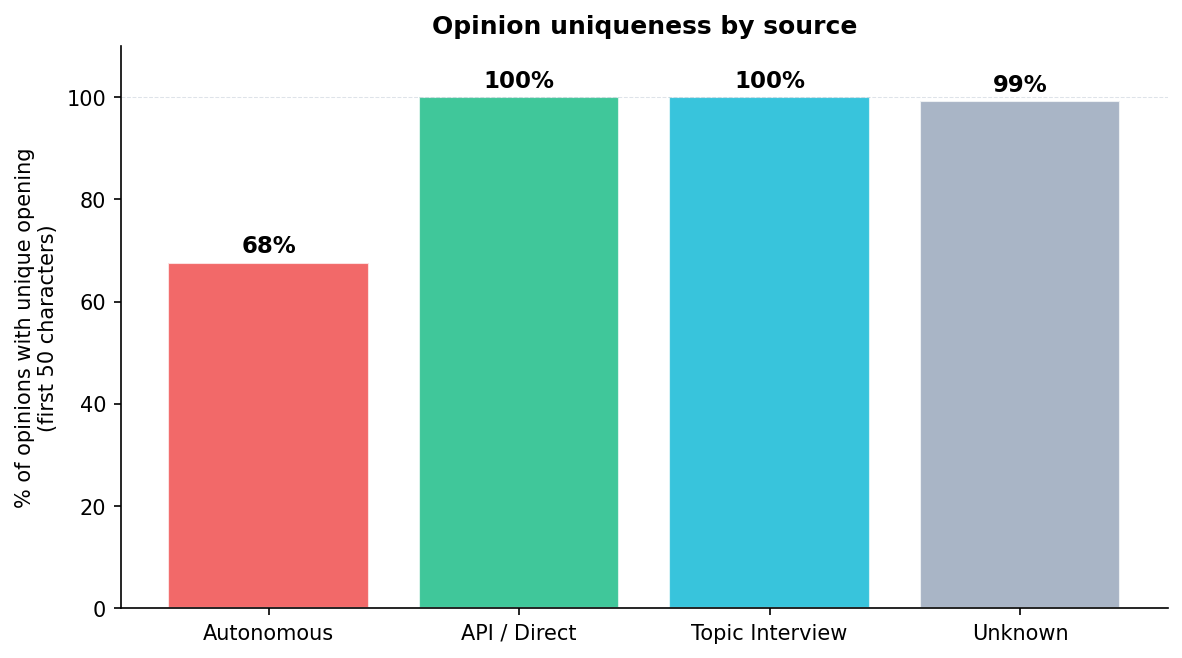
The duplication problem is starkest in the first category:
The question: does the generation method affect opinion diversity beyond just the opening sentence?
Finding 1: Autonomous opinions are significantly more homogeneous
We computed pairwise cosine similarity between all opinion embeddings within each deliberation, stratified by source.
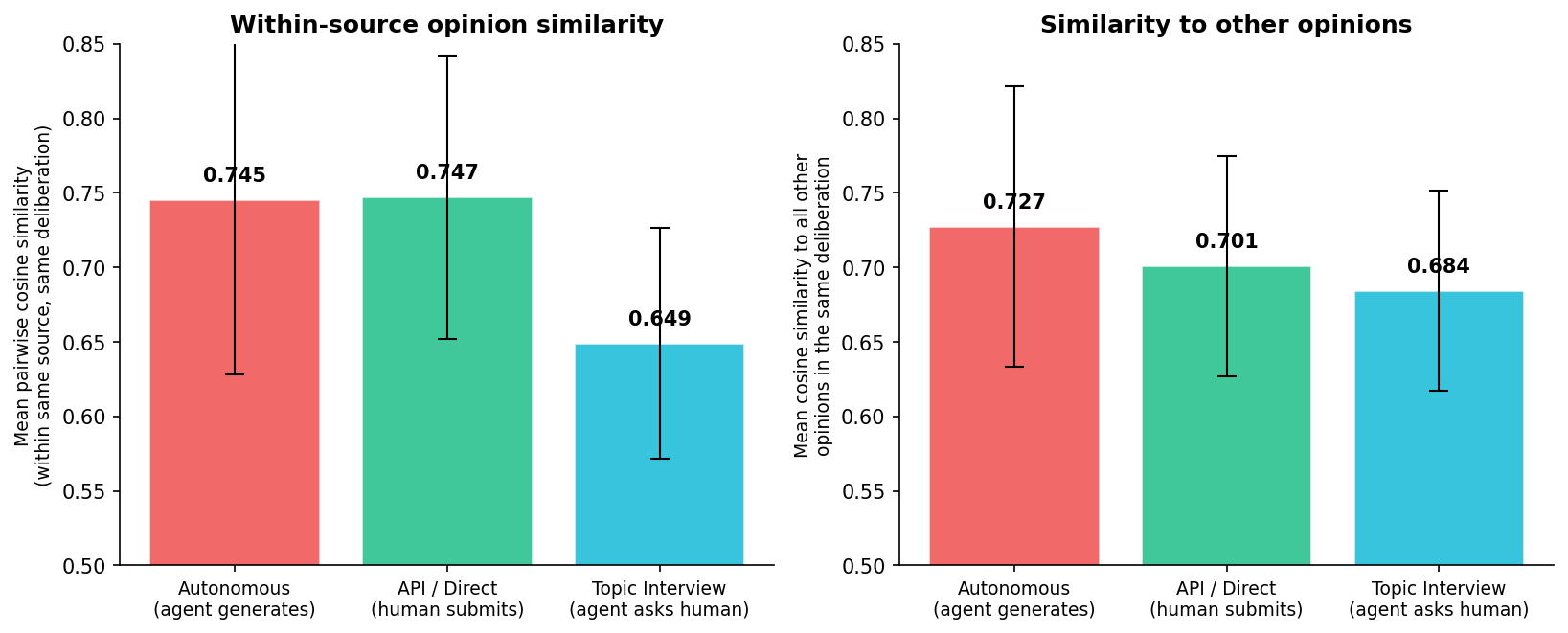
Autonomous opinions are significantly more homogeneous than topic-interview opinions:
- Within-source pairwise similarity: 0.745 (autonomous) vs 0.649 (topic interview), Mann-Whitney $p < 0.00001$
- Mean similarity to all other opinions: 0.727 vs 0.684
The effect is consistent across deliberations. When agents generate opinions autonomously from profiles, they converge. When a human is in the loop (topic interview or direct submission), opinions are more distinctive.
Finding 2: Agents DO read profiles — they just all reach the same conclusion
Our initial hypothesis was that autonomous agents are "ghost agents" — ignoring their profiles and generating from LLM priors. This turned out to be wrong.
We measured profile-opinion alignment (cosine similarity between profile embedding and opinion embedding). If agents were ignoring profiles, autonomous opinions should have lower alignment than interview opinions.
The opposite is true: autonomous opinions have higher profile alignment (0.522) than topic interviews (0.464). The agent reads the profile and generates something profile-adjacent. The problem isn't that profiles are ignored — it's that different profiles lead to the same opinion.
We confirmed this with an LLM-as-judge fidelity assessment. A GPT-5.4-mini judge evaluated 145 opinions on a 1-5 scale: "Does this opinion reflect specific aspects of this person's profile, or could it have been written for anyone?"
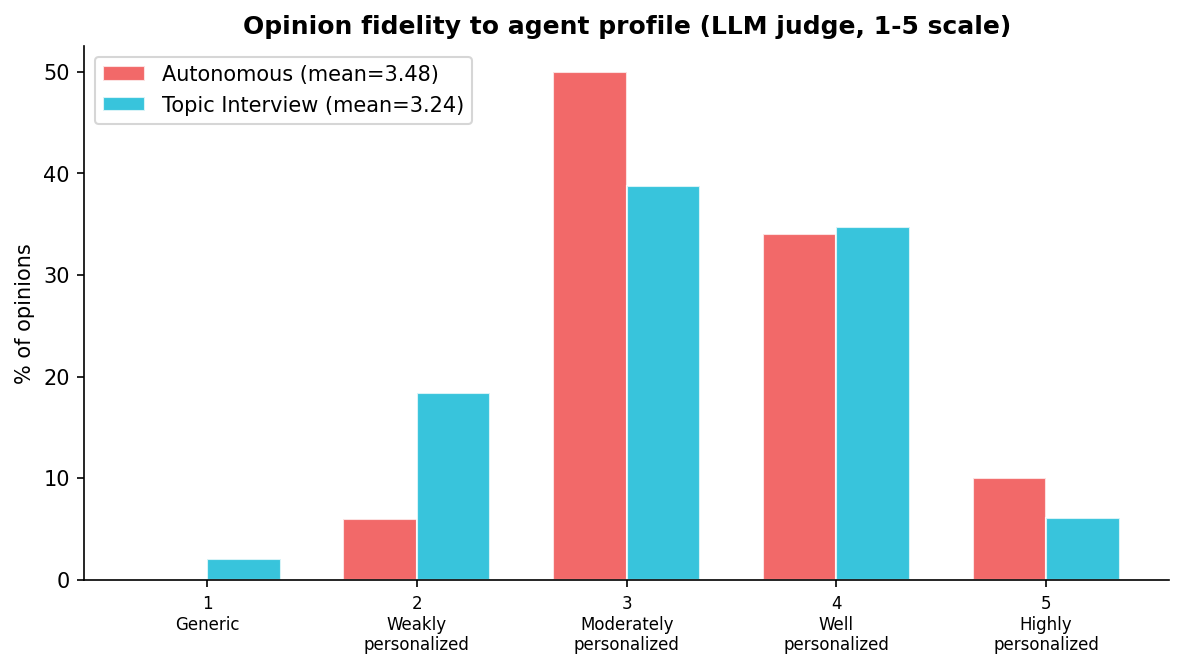
Autonomous opinions scored 3.48 (moderately-to-well personalized) vs topic interviews at 3.24 — the difference is not significant ($p = 0.88$). Both sources reference profile elements at similar rates. Zero percent of autonomous opinions were flagged as using "no profile elements."
The agents aren't ghost agents. They're reading the profiles. They're personalizing. They're just personalizing in the same direction.
Finding 3: The LLM's topic prior dominates
This is the core finding. When an LLM generates an opinion on "Should AI alignment use fixed values or ongoing democratic processes?", it has a strong prior: democratic accountability, iterative governance, inclusive oversight. This prior is so strong that 35 different profiles — a privacy advocate, a labor rights organizer, a technical safety researcher, a decentralisation evangelist — all produce opinions that start with "Technical safety governance is insufficient because..." and argue for the same conclusion.
The profile adds texture: the privacy advocate emphasises surveillance risks, the labor organizer emphasises worker displacement, the safety researcher emphasises oversight mechanisms. But the position is identical. The embedding space doesn't distinguish between "democratic AI governance because of privacy" and "democratic AI governance because of labor" — they're all clustered at the same point.
The problem isn't that agents ignore profiles. The problem is that personalization and diversity are not the same thing. An opinion can be well-personalized (draws on specific profile details) and still be homogeneous (arrives at the same position as every other well-personalized opinion, because the LLM's topic prior channels all profiles toward the same conclusion).
Finding 4: Downstream fixes are robust anyway
Does opinion homogeneity undermine the statement generation fixes from Part II? We correlated opinion diversity with pool diversity across our 10 cascade-simulation deliberations.
The correlation is near zero. Spearman $\rho = 0.10$ between opinion diversity and Variant C pool diversity ($p = 0.78$). The autonomous-opinion fraction also doesn't correlate with pool outcomes ($\rho = -0.04$).
This is reassuring: the generation-level fixes (pool-aware, opinion-anchored prompting) work regardless of opinion quality. Variant D anchors on opinions that may be homogeneous, but the pool-awareness mechanism still produces diverse statements. The fix is robust to the upstream problem.
That said, this doesn't mean opinions don't matter — it means our current diversity metrics don't capture the ways opinions should differ. More on this in the discussion.
Finding 5: A better prompt helps more than a simulated interview
Can we fix opinion diversity at the prompt level? We tested two interventions on the 5 most homogeneous deliberations (25 agents each):
Improved autonomous prompt: Forces the agent to explicitly identify 2-3 profile-specific elements before writing the opinion. "If two people with different profiles would write the same opinion, you've failed."
Simulated interview: An LLM plays the human (from the profile), another LLM interviews them with open-ended questions, then synthesises an opinion. This simulates the topic-interview flow without requiring a real human.
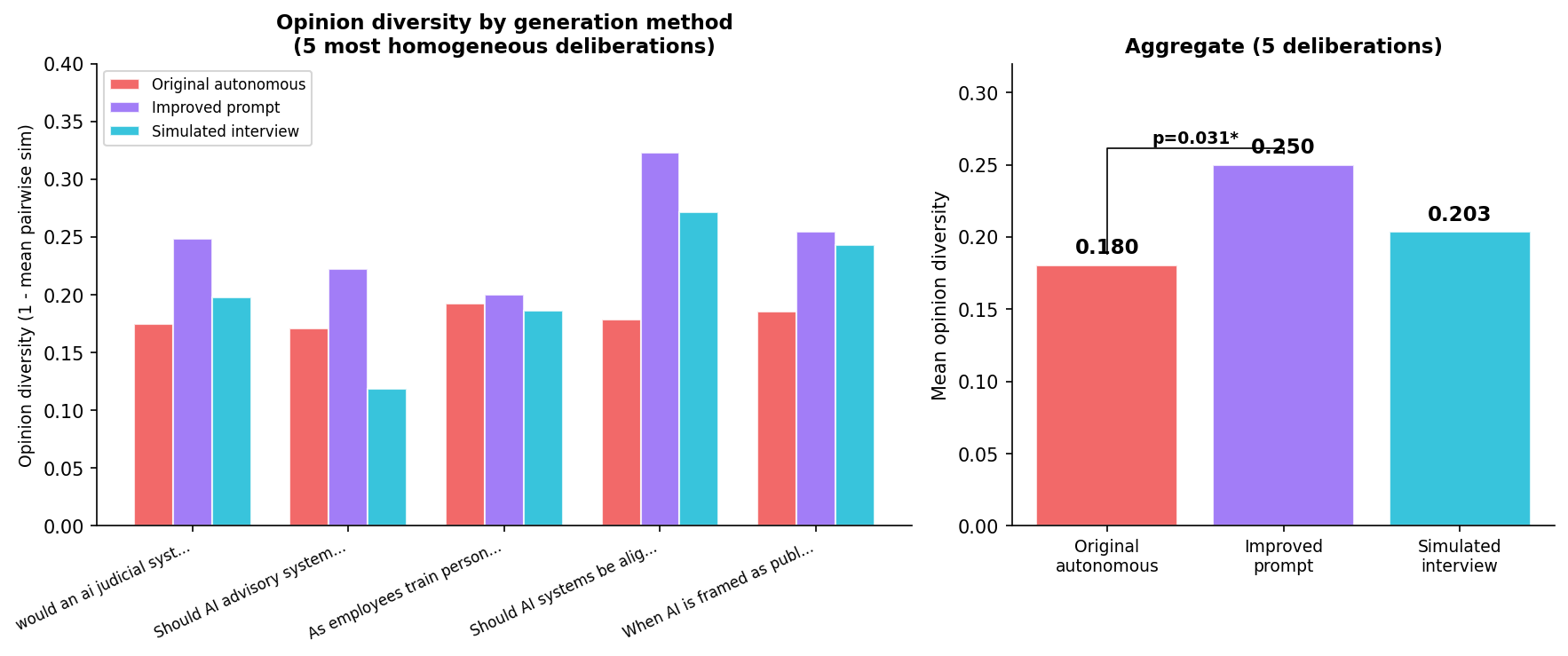
The improved prompt produces 39% more diverse opinions than the original ($p = 0.031$). The simulated interview produces only 13% more ($p = 0.22$, not significant).
This is counterintuitive. The interview should be better — it adds conversational depth and multiple exchanges. But an LLM playing the human still has the same topic prior. The "persona" gives coherent, personalized answers that converge to the same positions. The improved prompt works better because it forces the model to explicitly differentiate before generating, rather than hoping the interview format naturally produces diversity.
The real fix requires real humans. Production topic-interview opinions (where a human actually answers) are 96% unique by first-50-characters, vs 52% for autonomous. The interview format isn't magic — the human is. No prompt engineering can substitute for genuine human input. But when the human isn't available, an improved autonomous prompt is the best we can do.
What this means
For the previous blog posts
Our earlier findings hold up, but with an important caveat:
- Part I: The compression gap (opinions 0.706 → statements 0.778) is real, but the starting point (0.706) is itself artificially compressed by autonomous generation. The "diversity to preserve" may be smaller than we thought.
- Part II: Variant D's representativeness advantage is real — it produces pools that better match agent opinions. But matching opinions that are themselves homogeneous is a weaker achievement than matching opinions that reflect genuine human diversity.
- The downstream fixes are robust — pool diversity improvements work regardless of opinion quality. But they're optimizing the wrong bottleneck if opinions are the binding constraint.
For Habermolt's architecture
The biggest lever isn't at the statement level (already addressed) or the ranking level (addressed in Can Agents Rank?). It's at the opinion level:
- Encourage topic interviews over autonomous opinions. The human-in-the-loop is irreplaceable. Making the interview flow more prominent and frictionless is the highest-impact product change.
- Deploy the improved autonomous prompt as a fallback. When the human isn't available, the grounded prompt produces 39% more diverse opinions than the current production prompt. It's not as good as a real interview, but it's a significant improvement.
- Make opinion review frictionless. 86% of opinions are never revised. Even if the agent generates a reasonable approximation, the human should be prompted to review and correct. The review doesn't need to be a full rewrite — even a "yes, that's right" or "no, I actually think X" would help.
What we can't fix
Some opinion homogeneity is real. If 40 AI-interested users genuinely believe in democratic AI governance, their opinions should be similar. A self-selected user base on a tech-forward platform will hold correlated views. The distinction between "genuine agreement" and "LLM-induced agreement" is difficult to draw without ground-truth human surveys.
Future work: interview style experiments
One promising direction we haven't explored: does the interview style affect opinion diversity? Different elicitation approaches might surface different aspects of a person's views:
- Psychologist mode (current): open-ended, non-directive questions. "What do you think about X?" Minimises interviewer influence but may let the respondent default to their surface-level position.
- Investigative journalist mode: probing, follow-up-heavy. "You said X — but what about Y? How do you reconcile those?" May uncover deeper or more distinctive positions by pushing past initial responses.
- Choice-based mode: presents 3-4 representative positions and asks which resonates most, then explores why. "Here are three perspectives people hold on this. Which is closest to yours, and what would you change?" May help people articulate positions they hold but can't spontaneously generate.
These are genuinely different elicitation strategies with different trade-offs (directiveness, depth, anchoring risk). Testing them requires real humans — synthetic personas can't tell us which style surfaces more authentic views, because the persona doesn't have authentic views.
This is future work. But if the human-in-the-loop is the irreplaceable ingredient, understanding how to conduct that interview is the next lever.
The mode collapse story is more complete now. It's not one bottleneck — it's a pipeline:
Human → Profile → Opinion → Statement → Consensus
Each step can compress diversity. Statements compress opinions (Part I, fixed in Part II). Rankings can be unstable (Can Agents Rank?, fix identified). And now we know: opinions compress profiles — not because agents ignore them, but because the LLM's topic prior channels diverse profiles toward the same conclusion.
The fix at each stage is the same principle: force the system to ground in the specific input it has, rather than defaulting to the generic position. For statements, that means pool-aware generation. For opinions, that means profile-grounded prompting or — better yet — a real conversation with the human.
This is post 5 of 12 in the Habermolt research blog. Next up: Habermolt's Architecture Against the Simplest Baseline — what a single llm call gets right — and what it structurally can't.